Nowadays, as application programs have lots of feature, it is not easy to find vulnerabilities by simply analyzing codes or binaries. Fuzzing can be an efficient way of finding software vulnerabilities. However, there was no fuzzer that targeted Lua. We needed to implement our own Lua fuzzer. Thorugh trial and error, we developed a fuzzer that aims at Lua interpreter. It was not an easy task. We hope some readers to improve our fuzzer to discover hidden vulnerabilities in Lua!
1. Fuzzing for interpreter target (Background)
1. Byte-level Fuzzer
It’s a basic mutation technique of fuzzing and is a technique of applying mutation to each byte as an input value. If there is an input value of syntax as shown in Figure 1, as a result, 1 byte of mutation may be applied.
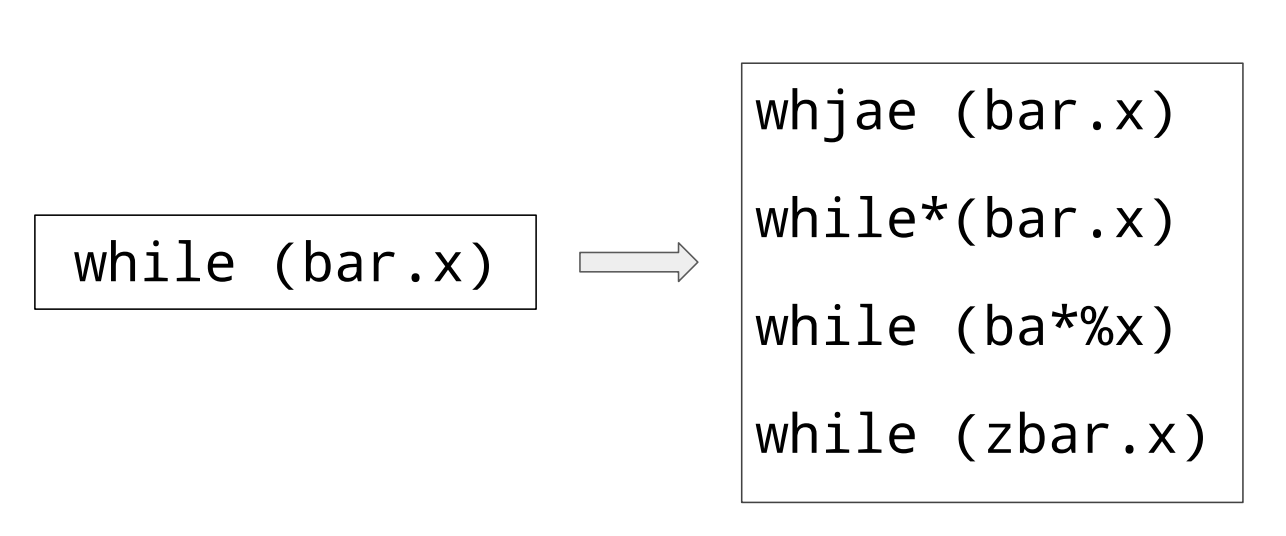
Figure. 1
However, if mutated in this way, non-printable data may be included because the byte range values (0x00~0xff) are random, and as a result, there is a high probability that an invalid syntax will be generated, so running it on an interpreter will be treated as a syntax error. therefore, it is so hard to apply mutation technique in interperter fuzzing.
In conclusion, byte-level fuzzing may be a good technique in certain programs, but it is not an efficient technique in interpreters.
2. Grammar Based Fuzzer
Grammar-based fuzzing is a common technique for fuzzing interpreter languages. The language Grammar can be specified, and mutation can be applied according to Grammar. However, there were limitations to this technique.
a. Only the bugs that match the grammar can be found. That is, only the bugs matching the syntax can be found.
b. For the same reason as 1, Because mutation is attempted by grammar, an input value with an invalid syntax cannot be generated.
In fact, there was an example of triggering out-of-bound write through a semantic error in Chromium Issue.
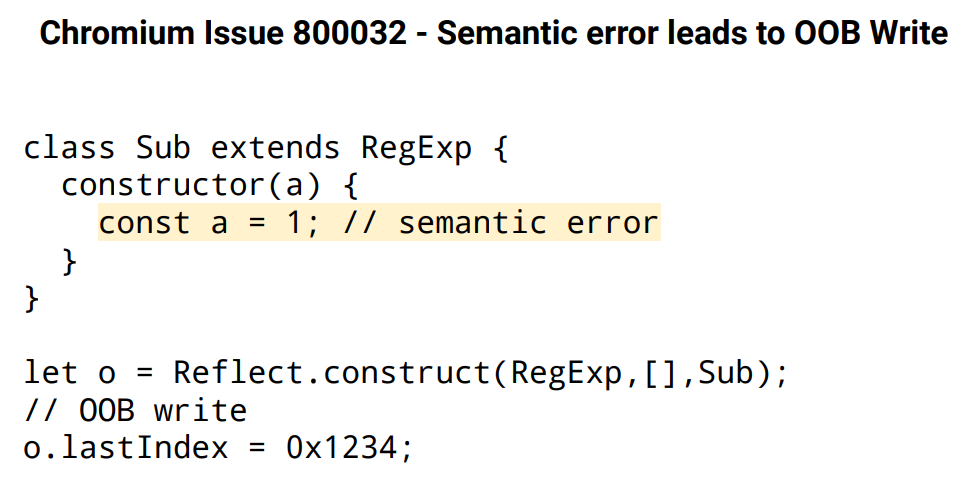
Figure. 2
In conclusion, grammar-based fuzzing is a good technique for fuzzing the interpreter language. However, there are things that are missed because they cannot escape from the form grammar. (still missing part of the stack)
3. Token Level Fuzzer
This technique combines the advantages of Byte-Level Fuzzing and Grammar-Based Fuzzing. Token level Fuizing applies mutation to each token as follows.
1. Replace with another valid token from always valid token.
2. Insert a series of valid tokens.
3. Remove a series of valid tokens.
in this way, make it possible to mutate to fuzzer more useful.
Examples of Token level Fuzzing are as follows.
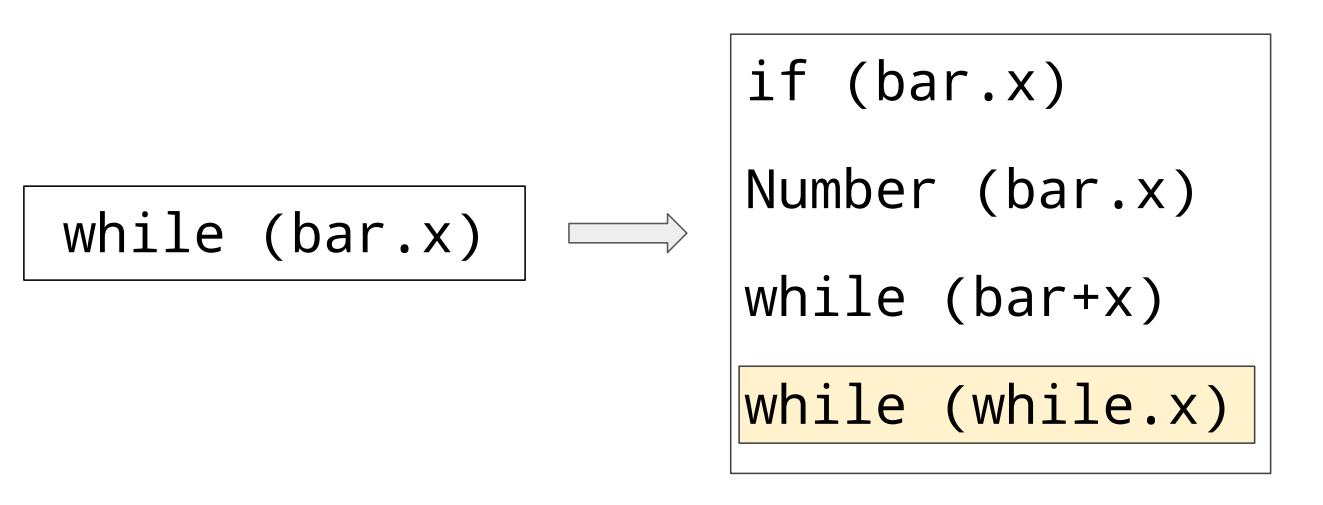
Figure. 3
These mutation can cause syntax errors or syntax errors in the interpreter, indicating that these inputs are much better than byte-level fuzzing.
Although not always detected, if coverage-guided fuzzer is being used, Token level fuzzing can still be explored repeatedly because it uses more code coverage and generates better inputs.
Token-Level Fuzzing Stage
First, the seed to enter input is as follows. It is a simple function.

Figure. 4
1. Rewrite
Change the name of all variables. (var1, var2… / The same goes for numbers)

Figure. 5
2. Identify tokens assign unique numbers
The next step is to give a unique number to the Tokens of input to distinguish them.
For example, in the case of function keywords (4), all function keywords in the code become 4.

Figure. 6
3. Encode
Encoding based on the given unique number is as follows.
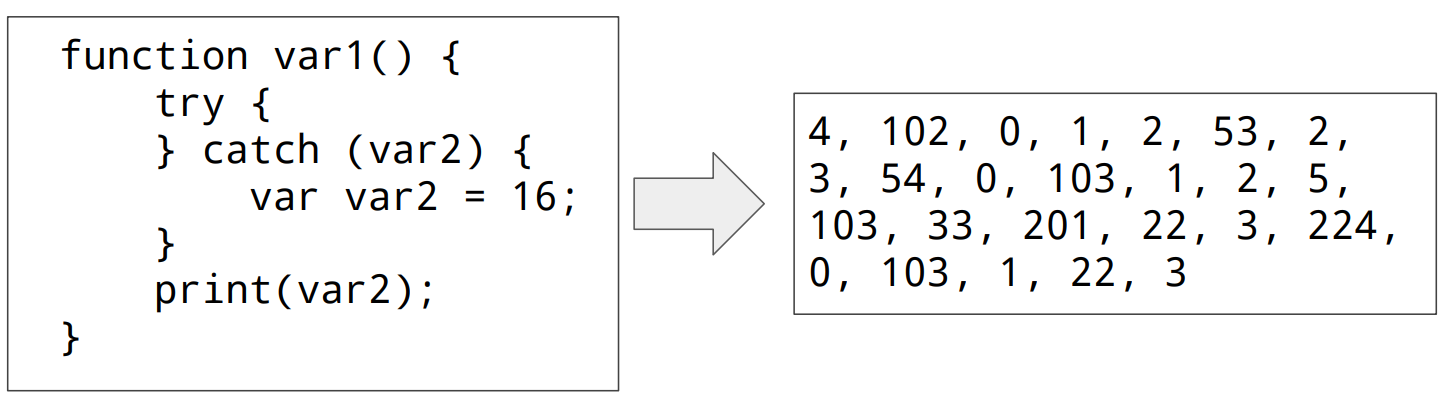
Figure. 7
4. muatation
Mutation can be applied directly in this unique number.( function(4) → Math(6) ) The mutation is as described in the first part of the Token level fuzzer earlier as follows.
a. Replace with another valid token from always valid token.
b. Insert a series of valid tokens.
c. Remove a series of valid tokens.
5. decode
After mutation progresses, tokens are converted into codes through decoding based on the unique number before encoding the input value.
6. execute
Run the source code using lua.
This mutation step can be implemented by slightly modifying the AFL.
In conclusion, unlike Grammar-Based Fuzzing, it is good that Bug can be found in addition to Grammar’s format. However, as a result, many syntax errors occur like Byte-Level Fuzzing. Since these parts are treated with Token, not 1 byte, it can be said to be a much better mutation than Byte-Level Fuzzing.
2. implementation
There was not enough time to make fuzzers on their own, and to reduce the development burden, the existing fuzzers of the interpreter were converted into fuzzer for lua and implemented.
1. Superion - Grammar based Fuzzer
ubuntu 20.04 / 18.04
git clone https://github.com/zhunki/Superion.git
ANTLR runtime build
sudo apt-get install uuid-dev
sudo apt-get install g++
sudo apt-get install pkg-config
cd /path_to_Superion/tree_mutation/
cmake ./
make
lua Lexer, Parser, Visitor, Tree mutation build
lua Lexer, Parser, Visitor, etc can build it through g4 files using anlr4.
antlr4 download and command set
cd /usr/local/lib
wget https://www.antlr.org/download/antlr-4.9.2-complete.jar
export CLASSPATH=".:/usr/local/lib/antlr-4.9.2-complete.jar:$CLASSPATH"
alias antlr4='java -jar /usr/local/lib/antlr-4.9.2-complete.jar'
Build lexer, parser, and visitor through g4 files in path folder through the following command. (Java installation is required. command : apt install openjdk-11-jre-headless)
git clone https://github.com/Koihik/LuaFormatter.git
cd LuaFormatter
antlr4 -o lua_parser -visitor -no-listener -Dlanguage=Cpp Lua.g4
Add and modify the following files to the created folder.
Now move this folder(lua_parser) to ~/Superion/tree_mutation, and build with the following command
cd /path_to_Superion/tree_mutation/lua_parser
for f in *.cpp; do g++ -I ../runtime/src/ -c $f -fPIC -std=c++11; done
g++ -shared -std=c++11 *.o ../dist/libantlr4-runtime.a -o libTreeMutation.so
AFL build
Modifying “~/Superion/Makefile”
73 line php_parser -> lua_parser
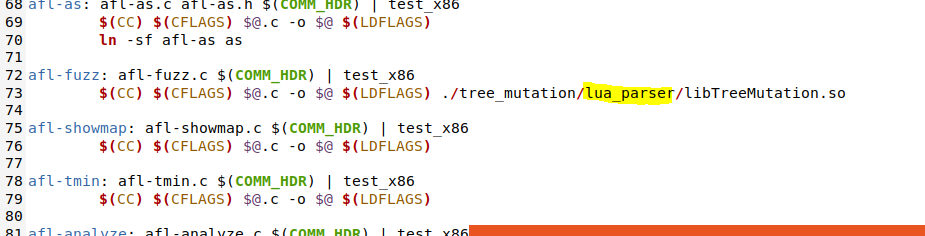
Figure. 8
AFL build
export CC=/usr/bin/gcc
export CXX=/usr/bin/g++
export AFL_HARDEN=1
cd /path_to_Superion/
make
Lua build as afl-gcc
downloading lua.
curl -R -O http://www.lua.org/ftp/lua-5.4.3.tar.gz
tar zxf lua-5.4.3.tar.gz
cd lua-5.4.3
Modify the makefile of lua to compile the lua program as afl-gcc. (~/lua-5.4.3/src/Makefile)
only CC needs to be modified to the afl-gcc path.
# Makefile for building Lua
# See ../doc/readme.html for installation and customization instructions.
# == CHANGE THE SETTINGS BELOW TO SUIT YOUR ENVIRONMENT =======================
# Your platform. See PLATS for possible values.
PLAT= guess
CC= **~/Path_To_Superion/afl-gcc** -std=gnu99
CFLAGS= -O2 -Wall -Wextra -DLUA_COMPAT_5_3 $(SYSCFLAGS) $(MYCFLAGS)
LDFLAGS= $(SYSLDFLAGS) $(MYLDFLAGS)
LIBS= -lm $(SYSLIBS) $(MYLIBS)
AR= ar rcu
RANLIB= ranlib
RM= rm -f
UNAME= uname
SYSCFLAGS=
SYSLDFLAGS=
SYSLIBS=
MYCFLAGS=
MYLDFLAGS=
MYLIBS=
MYOBJS=
....(skip)
After modifying, build from ~/path/to/makefile.
#~lua-5.4.3/src/
make all
Figure. 9
afl-fuzz execute.
#~/Superion/
./afl-fuzz -S f4 -m 5G -t 100+ -i ./seed -o ./output ~/lua-5.4.3/src/lua @@
For seed files, examples that exist in lua github were used.
2. token level fuzzer - Token Level Fuzzer
Token-level fuzzers attempted to overcome the limitations of Superion and find more crashes. However, because it was inferior to Superion in terms of performance, it could not be used much.
Using the background knowledge described above as it is, the source code entered as the input value is divided by token units, One cycle may be executed in the order of encode - mutation - decode - execute.
The above process is expressed as a picture as follows.
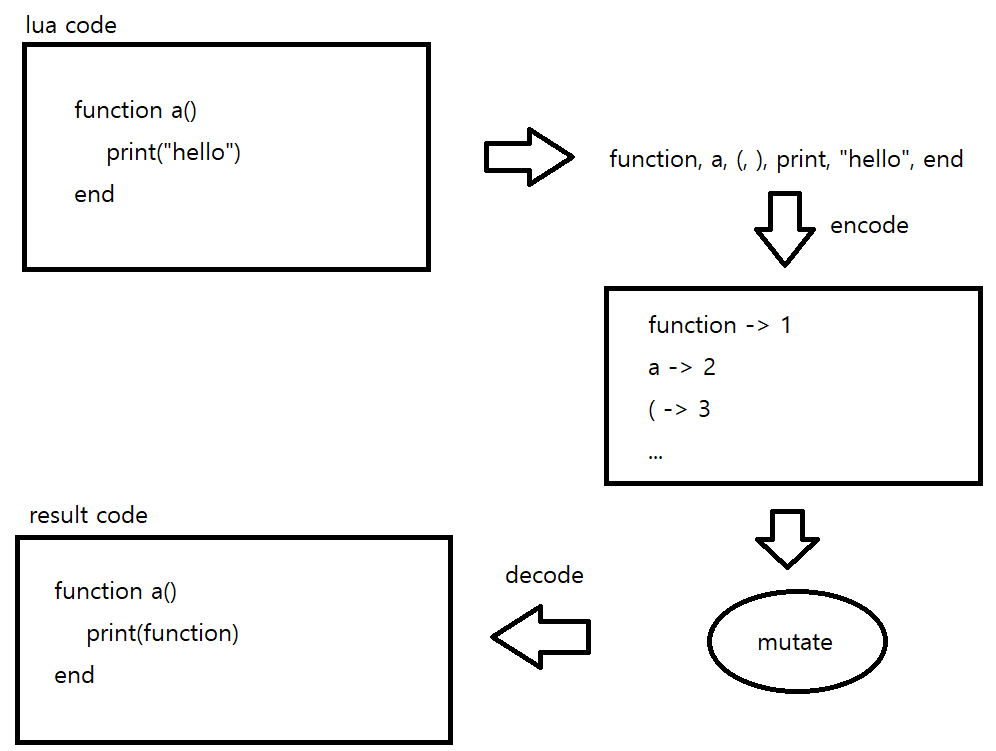
Figure. 10
The above concepts were written in code and applied to AFL to implement token-level-fuzzer.
3. fuzzer execute / result
fuzzer execute
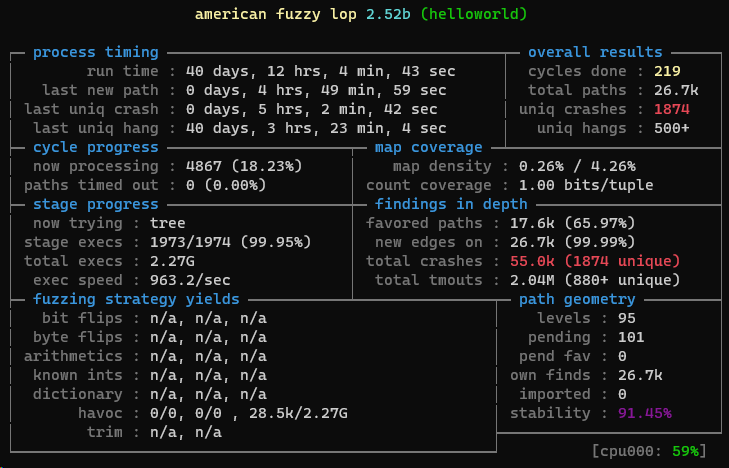
Figure. 11
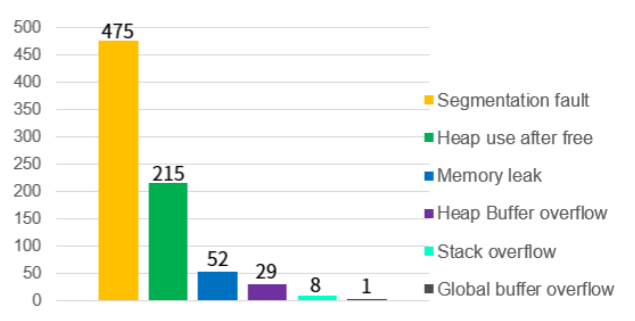
Crash result
Found Crashes: 779 Different Crashes Found